
Why transform data?
Data transformation is a process of converting raw data into a unified format to facilitate easy analysis and integration with other systems.
Every business generates a large amount of data daily, but the data is not useful until it is transformed into a useful format. To get benefits from raw data, transformation is necessary.
Transformation involves several steps to convert the data into the desired format. In some cases, data must first be cleansed before it can be transformed. Data cleansing prepares the data for transformation by resolving inconsistencies or missing values.
Once the data is cleansed, the following steps in the transformation process occur:
1. Data Discovery:
The first step in the data transformation process consists of identifying and understanding the data in its source format. This is usually accomplished with the help of a data profiling tool. This step helps you decide what needs to happen to the data in order to get it into the desired format.
2. Data mapping:
The actual transformation process is planned.
3. Generating code:
For the transformation process to be completed, code must be created to run the transformation job. Often these codes are generated with the help of a data transformation tool or platform.
4. Executing the code:
The data transformation process that has been planned and coded is now put into motion, and the data is converted to the desired output.
5. Review:
Transformed data is checked to make sure it has been formatted correctly.
In addition to these basic steps, other customised operations may occur.
-
- Filtering (e.g. Selecting only certain columns to load).
- Enriching (e.g. Full name to First Name , Middle Name , Last Name).
- Splitting a column into multiple columns and vice versa.
- Joining together data from multiple sources.
- Removing duplicate data.
Transforming Data. Transforming Teams.
intelia has partnered with dbtLabs – DBT (data build tool) provides a framework to develop data pipelines that transform data using code that is managed, easy to collaborate with and scalable.
DBT provides a way to work with transformations the same way application developers work to develop code – providing agility and complete traceability.
How can intelia help?
intelia & dbtLabs Partnership
intelia is a dbtLabs Delivery partner with consultants trained and delivering enterprise solutions across APAC. We believe dbtLabs is a core part of the next generation data stack – allowing for the transformation of data with agility and complete traceability.
Contact us for a no-obligation chat about dbtLabs and our other data & analytics service offerings.
Why dbt?
Today’s markets offers several tools to achieve data transformation. Yet, the one that clearly stands out is dbt or the data build tool. The DBT tool will help you achieve the transform part of the ETL/ELT process with relative ease and speed.
- Data Build Tool can be used by anyone who has the knowledge and skill to write SQL select statements. Using this expertise, they can build data models, write tests, and plan jobs to deliver actionable, consistent, and reliable datasets to drive analytics.
- dbt is like an orchestration layer over the data warehouse that enhances and increases the pace of your organisation’s data transformation, including its integration.
- dbt works by performing all the calculations and computations at the very basic database level. So, the complete task of data transformation is completed more rapidly, and securely all the while maintaining its integrity.
- dbt is a developmental framework that enables data analysts and engineers to transform data in their warehouses simply by writing SQL statements. It makes data engineering endeavors available to data analysts.
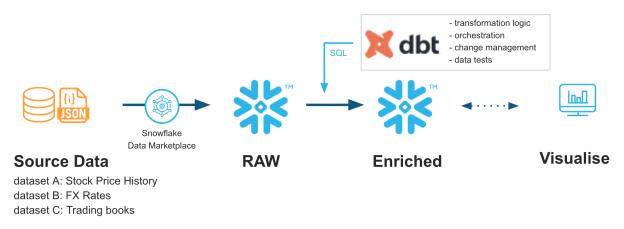
What makes dbt powerful?
Data Build Tool supports several databases like Snowflake, BigQuery, Postgres, Redshift, Presto, etc., and is easy to install using Python Package Installers or pip as it is more often called.
dbt is an open-source application written in Python, giving the users the power to customize it as needed.
A dbt user only needs to focus on writing select queries or models to reflect the business logic. You don’t have to write sections of repetitive code that are used occasionally with no variations. To be precise, it does away with the need for writing boilerplate code for creating tables and views and specifying the execution order of the written models. dbt takes care of it by:
-
- Changing the models into objects that reside in your organisation’s data warehouse.
- Processing the boilerplate code to set up queries as relations.
- Providing a mechanism for executing data transformations in an orderly and step-by-step form using the “ref” function.
It also offers a lot of flexibility to the users. Say, for example, the resultant project structure is not a match for your organisational needs. You can customise it by editing the dbt_project.yml file or the configuration file and rearranging the folders.
Advantages of dbt
-
- You can easily apply version control to it.
- It is open source and hence customisable.
- It does not have a steep learning curve.
- It is well documented, and the documentation stays with the dbt project. It is automatically generated from the codebase.
- No specific skill sets are required other than familiarity with SQL and basic knowledge of Python.
- The project template is automatically generated through dbt init, standardising it for all data pipelines .
- Orchestrating a dbt pipeline involves the use of minimal resources as the data warehouse handles all computational work.
- It allows the users to test the data and, in turn, ensures data quality.
- A complex chain of queries can be debugged easily by splitting them into easy-to-test models and macros.
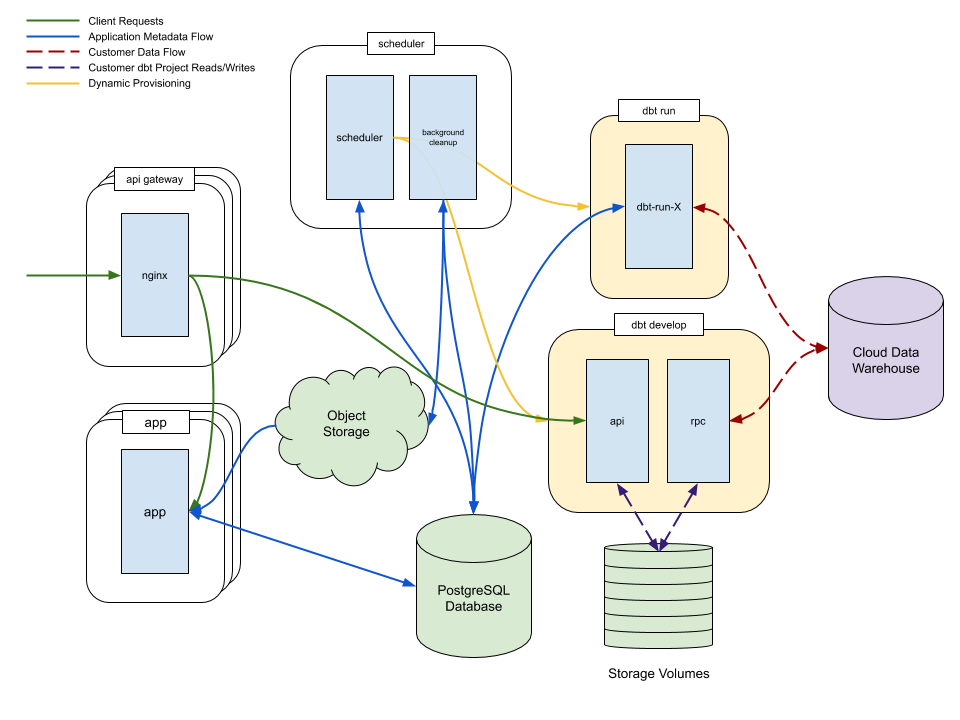
Architecture
Global Case Studies
Case Study 1
The Challenge
Snowflake’s data lake serves as the central storage for all HubSpot’s data, “We’re pulling in data from our in-house databases, APIs, a lot of flat files sitting in S3, and Kafka streams. It all lands in our Snowflake data lake,” said James. Snowflake makes managing this data easy, but with that set of problems out of the way, HubSpot’s data team started to feel pressure in another part of the ELT stack–transformation.
The early attempt at solving this blocker was using Apache Airflow to build and deploy SQL models. The combination of Snowflake and Airflow meant that highly technical analysts could build data sets without going through data engineers, but the process opened up new problems like messy code base, Difficulty determining model dependencies, challenging to troubleshoot. Even with best-in-class data warehousing, analytics velocity remained slow. HubSpot still had a huge gap between where they were and where they wanted to be in their journey toward empowering analysts.
The Solution
Ultimately, it was the analyst community at HubSpot who discovered the secret to owning their own tooling–dbt. Two teams in particular were eager to start using dbt so the infrastructure team got things up and running.
These early adopters found that dbt empowered them in three important ways:
1. Empowered to do data modeling the right way
dbt provided the technical infrastructure for analysts to own data transformation along with a set of best practices.
2. Empowered to define model dependencies
With Airflow, defining model dependencies was limited to data engineers or the most technical analysts. In dbt, model dependencies are defined using a “ref” function to indicate when a model is “referencing” another model. dbt sees these references and automatically builds the DAG in the correct order.
3. Empowered to update and troubleshoot models
The ease of referencing models ends up, “totally changing the way people write SQL,” James said. When dependencies are easy, analysts start to break their queries into smaller pieces.
Results
In addition to getting more analyst teams using dbt, James’ team is also migrating HubSpot’s testing infrastructure to dbt. “We have a legacy testing framework that works quite well for us. But being separate from dbt, it doesn’t make a lot of sense,” James said. “We’re currently adopting the dbt testing framework so analysts will be able to write their own data quality tests as well.”
Case Study 2
The Challenge
Jacob, the data analyst #1 at Firefly Health with the intention to build an analytics team that was not only rewarding to be a part of but would have a significant impact on the business. At Firefly Health, Jacob would be a team of one. This felt foreign, but empowering. “In my previous role an analyst would make a request, the request would drop into an engineer’s backlog, and three weeks later a new dimension would appear, often lacking any understanding of the original business context”.
With Snowflake, Fivetran, and Looker in place, Jacob found he could operate as a team of one.
The tradeoff was there was a dramatic increase in the volume of low-leverage tasks he faced daily. Cleaning was tedious, testing was ad-hoc, and “quick questions” from stakeholders could consume entire afternoons. The new stack worked, but the “bubble gum and tape” method he crafted wouldn’t scale. “To expect anyone new to understand the pipeline I had created, would have been tough. It was just this mysterious analytics server managed by me. I really needed a way to ensure consistency as the team grew”.
The Solution
When searching for the missing piece of the data stack that would help him expand his team, Jacob was guided by three core requirements:
1. Data must inform product direction, not just report on it.
2. Data engineering must be self-serve for analysts. Data insights must be self-serve for the entire organization.
3. As a former developer, Jacob immediately recognised the value of dbt Cloud’s analytics engineering workflow. Job scheduling, reusable code, and continuous delivery help him increase analytic velocity. Regimented testing, code review, and integrated documentation provide the “reliability” element reminiscent of his developer days. “dbt Cloud solves all those problems for me. It makes me feel like I’m spending more time delivering business insights than managing infrastructure, trying to pinpoint errors in formatting, or deciphering why a job failed”.
Results
In the 12 months prior to dbt the Firefly team created 4 new data models. Two months into their use of dbt, they’ve created 15.
dbt helped the team increase analytic velocity without sacrificing quality.
Contact us for a no-obligation chat about dbt Labs and our other data & analytics service offerings.